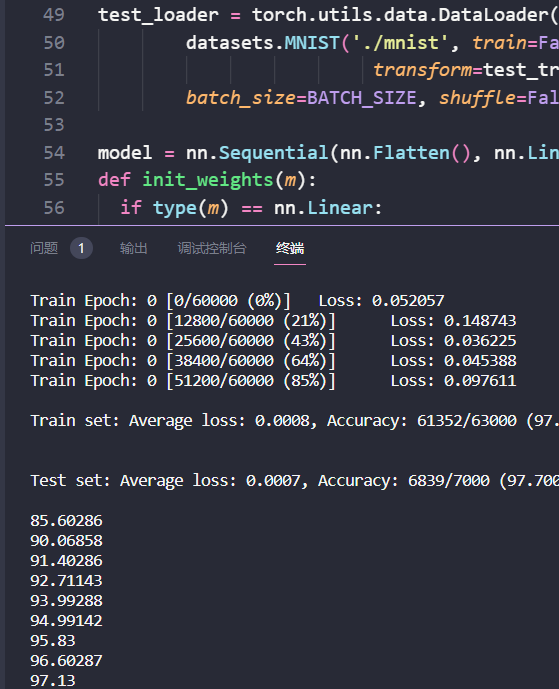
def train(model, optimizer,criterion,epoch): model.train() # setting up for training for batch_idx, (data, target) in enumerate(train_loader): # data contains the image and target contains the label = 0/1/2/3/4/5/6/7/8/9 data = data.view(-1, 28*28).requires_grad_() optimizer.zero_grad() # setting gradient to zero output = model(data) # forward loss = criterion(output, target) # loss computation loss.backward() # back propagation here pytorch will take care of it optimizer.step() # updating the weight values if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))
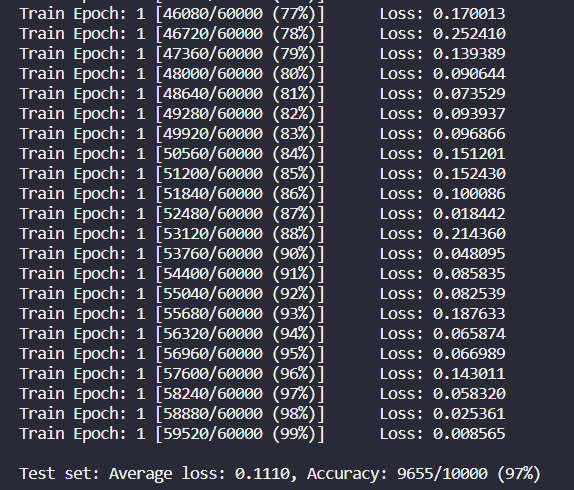
with torch.no_grad(): for batch_idx, (data, target) in enumerate(val_loader): data = data.view(-1, 28*28).requires_grad_() output = model(data) test_loss += criterion(output, target).item() # sum up batch loss pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() # if pred == target then correct +=1
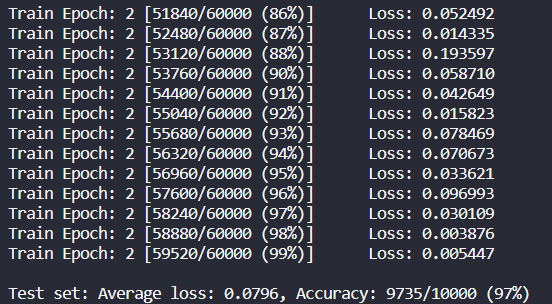
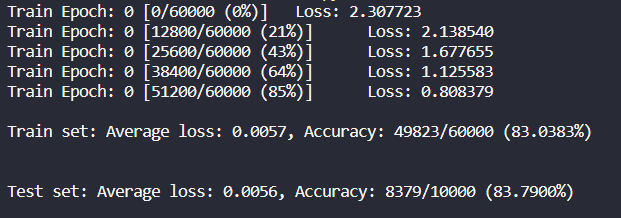
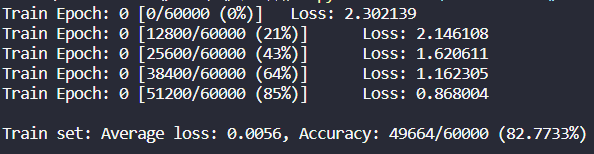
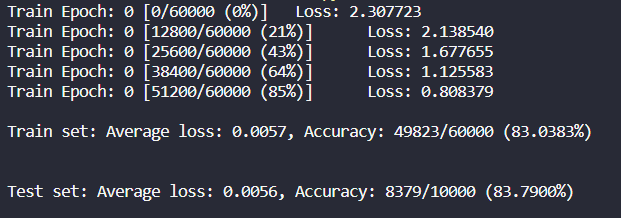
test_loss /= len(val_loader.dataset) # average test loss if train == False: print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format( test_loss, correct, val_loader.sampler.__len__(), 100. * correct / val_loader.sampler.__len__() )) if train == True: print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format( test_loss, correct, val_loader.sampler.__len__(), 100. * correct / val_loader.sampler.__len__() )) return 100. * correct / val_loader.sampler.__len__()
def forward(self, x): x = self.conv(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout(x) x = torch.flatten(x, 1) x = self.fc(x) output = F.log_softmax(x, dim=1) return output
def train(model, optimizer,criterion,epoch): model.train() # setting up for training for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28*28).requires_grad_() optimizer.zero_grad() # setting gradient to zero output = model(data) # forward loss = criterion(output, target) # loss computation loss.backward() # back propagation here pytorch will take care of it optimizer.step() # updating the weight values if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))
先注意到因為 training 和 testing 時 model 會有不同行為,所以用 model.train() 把 model 調成 training 模式。
def hold_out(images, labels, train_percentage): test_acc = torch.zeros([Iterations]) train_acc = torch.zeros([Iterations]) ## training the logistic model for i in range(Iterations): train(model, optimizer,criterion,i) train_acc[i] = test(model, criterion, train_loader, i,train=True) #Testing the the current CNN test_acc[i] = test(model, criterion, test_loader, i) torch.save(model,'perceptron.pt')
def train_flod_Mnist(k_split_value): different_k_mse = [] kf = KFold(n_splits=k_split_value,shuffle=True, random_state=0) # init KFold for train_index , test_index in kf.split(dataFold): # split # get train, val train_fold = torch.utils.data.dataset.Subset(dataFold, train_index) test_fold = torch.utils.data.dataset.Subset(dataFold, test_index)
# package type of DataLoader train_loader = torch.utils.data.DataLoader(dataset=train_fold, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_fold, batch_size=BATCH_SIZE, shuffle=True) # train model test_acc = torch.zeros([Iterations]) train_acc = torch.zeros([Iterations])
## training the logistic model for i in range(Iterations): train(model, optimizer,criterion,i) train_acc[i] = test(model, criterion, train_loader, i,train=True) #Testing the the current CNN test_acc[i] = test(model, criterion, test_loader, i) #torch.save(model,'perceptron.pt') # one epoch, all acc different_k_mse.append(np.array(test_acc)) return different_k_mse
按循序打印结果
1 2 3 4 5 6
testAcc_compare_map = {} for k_split_value in range(2, 10+1): print('now k_split_value is:', k_split_value) testAcc_compare_map[k_split_value] = train_flod_Mnist(k_split_value) for key in testAcc_compare_map: print(np.mean(testAcc_compare_map[key]))
def forward(self, x): x = self.conv(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout(x) x = torch.flatten(x, 1) x = self.fc(x) output = F.log_softmax(x, dim=1) return output






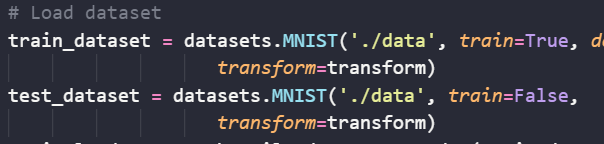

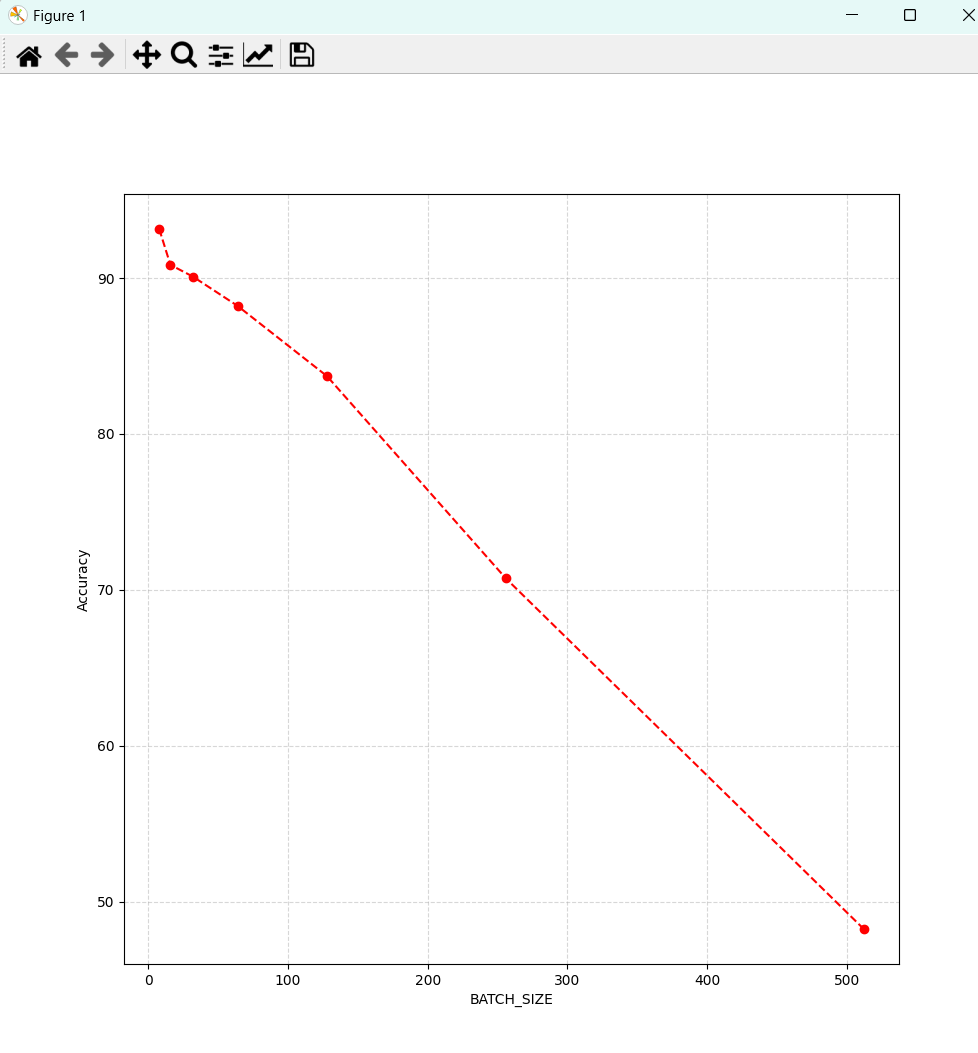
 学习率
学习率